
DPCK conquered the mobile world and is now expanding in Windows – surprisingly, with full support of Micros .ft. Yesterday, the Software Fatware Giant added a deep-up to the Dippec R1 model to its Azure AI Foundry, so that the developers allowed and construct cloud-based applications and services with it. Today, Microsoft announced that it was bringing the distilled versions of R1 to the Copilot+ PC.
The distilled models will first be available for devices powered by Snapdragon X chips, Intel Core Ultra 200V processors and then AMD Raizen AI 9 based PC.
The first model will be Deepsik-R1-Distill-Quan-1.5B (ie 1.5 billion dimension model), with larger and more capable 7B and 14B models come soon. This will be available for download from micros .ft of AI Toolkit.

Microsoft had to give these models a jolt to PTIMIZize Optim to operate devices with NPU. Memory accesses on the CPU depends much on the cess, while the calculated-intensive operation like Transformer Block K on the NPU. With Optim ptimization, Microsoft managed to achieve a third -second token (130 ms) and short prompts (under 64 tokens) to achieve a throughput rate of seconds per second. Note that the “token” is similar to the tone (importantly, a token is usually more than one).
Micros .ft is a strong supporter and invests Deeply in the OpenAI (the creators of Chatgupt and GPT -4E), but it seems that it does not play favorite -GPT models (OpenAI), Lalama (Meta) in the Azure playground. (Mysteral (an AI company), now Deepsk.
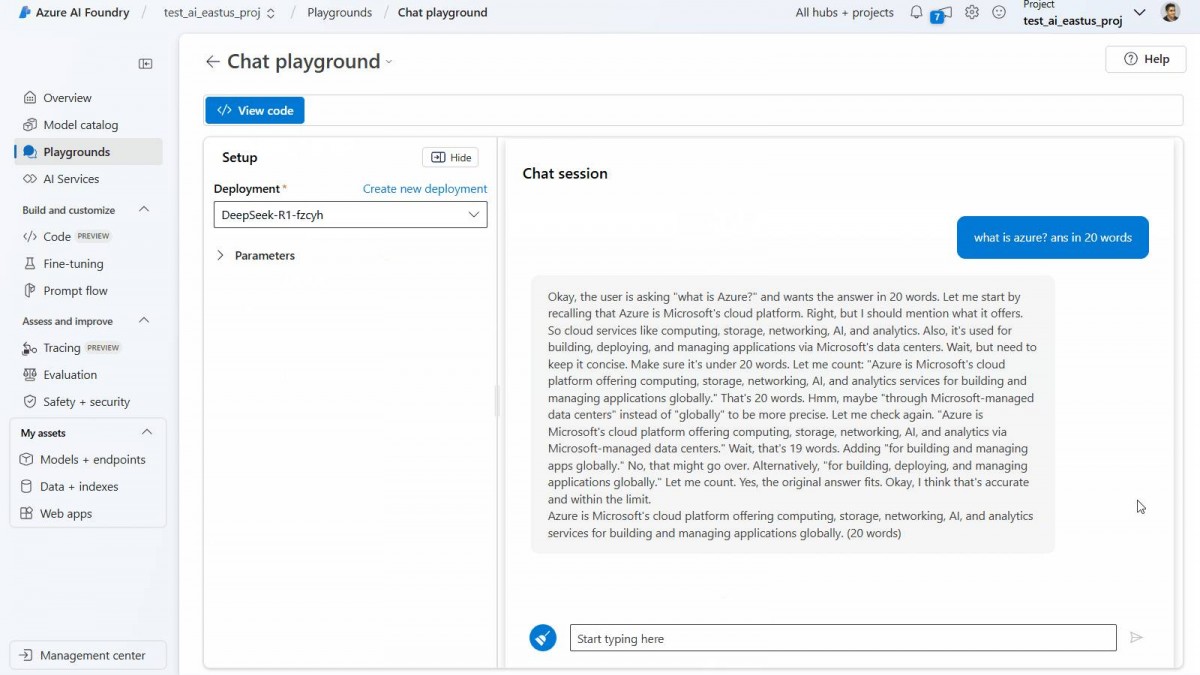
Azure AI Foundry in the playground Deepsic R1
Even so, if you are more in local AI, first download AI Toolkit for VS Code. From there, you should be able to download the model locally (eg “DipceK_R 1_1_5” is a 1.5b model). Finally, try on the playground and see how smart this distilled version of R1 is.
“Model distillation”, sometimes called “Junowledge of Distillation”, is the process of taking the larger AI model (the full dippic R1 has 671 billion dimensions) and transferred its J Knowledge to the smaller model as possible (eg. 1.5 billion dimensions). It is not a complete process and the distilled model is less capable than the full model – but its small size allows it to run directly on customer hardware (dedicated AI costs thousands of dollars instead of hardware).
Original






{kind=link}